
简介
解码器(decoder)是语音识别中非常重要的一部分,我个人觉得这也是语音识别区别于图像识别等其他方向的一个主要方面。训练好的模型需要通过解码器的巧妙设计组合才能最后实现一套完整的语音识别流程。虽然说近年来端到端的语音识别框架越来越完善,除去其简洁的建模训练过程,在识别率上大有赶超传统Hybrid语音识别的趋势。但是,以WFST解码器为代表的解码过程还是非常的经典,尤其是对声学模型及语言模型的结合,以及在解码时对解码路径的可操作性都非常值得我们去学习掌握。本篇主要根据自己的理解,简要记录一下WFST解码器是如何通过在图上进行路径搜索并实现解码的(Kaldi SimpleDecoder),由于对HCLG图的构建理解比较浅显所以暂不涉及,如有不同理解的欢迎讨论指正。
Token Passing 与维特比解码
传统的Hybrid语音识别中利用了HMM去表示人在讲话时发音序列的状态转变,在学习HMM时一般会提到三个问题:概率计算问题,学习问题,预测问题,其中预测问题也就是我们所说的解码。HMM中常常利用维特比算法来解决预测问题:给定已知模型$\lambda=(A,B,\pi)$和观测序列$O=(o_1,o_2,…o_r)$,求条件概率$P(I\mid O)$最大的状态序列,在ASR解码中也就是给定一组提取的连续语音特征求其对应的音素状态序列。
如果不考虑如何将HMM状态由音素扩展到人可以理解的词及句子,单纯的以音素为最小建模单元,维特比解码会按照时间序列$t=2,3…T$计算每个时间点$t$的最大概率$\delta_t(i)$,并回溯出一条概率最大的最优路径。但是,ASR中的路径搜索要比这复杂的多,传统的解码器在提取每帧的音频特征后,要遵循音素、词、句子的顺序进行解码,在解码过程中需要考虑到不同层级的映射关系。如果在解码过程动态映射匹配效率会比较低,于是引入了前面提到的HCLG静态图,通过对语音识别需要动态集成的HMM、词典、语言模型等知识源进行预先编译,形成一个静态图网络,在解码时预先加载结合每帧计算的声学得分即可直接在图上进行由音素到句子的映射。
一种维特比算法的朴素实现,通常是建立一个$T*S$的矩阵,$T$为帧数,$S$为$HMM$的状态总数。解码时需要对声学特征按帧遍历,对于每一帧的每个状态,把前一帧各个状态的累计代价和当前帧在当前状态下的代价累加,选择使当前帧代价最低的前置状态最为当路径的前置状态直至最后一帧。但在语音识别中,并不需要始终存储整个矩阵的信息,而只保留当前帧及上一帧的信息即可,有一种更加灵活的算法来实现的维特比算法,即令牌传递(Token Passing)算法。
WFST的维特比解码
WFST解码中Token Passing本质上也是维特比解码,它根据输入的特征帧序列${o_1,o_2,…,o_T}$,进行帧同步对齐,需求最佳状态序列${S_1,S_2,..S_N}$。需要注意的是这里的状态需要跟HMM中的状态区分开来,此处的状态代表融合后HCLG图中的状态节点,如图,所遍历状态节点直接的弧,可能是产生观察值(例如输出olabel可以为音素,字等)的发射弧(图中状态$S_1,S_2$之间的实线),也可能是不产生观察值的非发射弧(图中虚线)。

Token(令牌)是一种与HCLG状态节点相关联的数据结构,Token的设计可以在保留遍历路径的基础上节省存储空间。以Kaldi SimpleDecoder中的Token结构为例子,其包括arc,prev,ref_count, cost四个成员。arc是对原有FST中弧的复制;利用prev指针可以对HCLG的状态节点路径进行追溯;ref_count可以用在垃圾回收算法中;cost则是对截至当前状态节点路径上代价的累计存储。
struct Token {
Arc arc; //Token间的转移弧
Token *prev; //指向上一时刻的Token的指针
int32 ref_count; //后续关联的token数量
double cost; //累计代价
}
struct Arc {
int ilabel; //转移弧上的输入标签
int olabel; //转移弧上的输出标签
float weight; //转移弧权重
int nextstate; //转移弧连接的下一个状态
}
类似于HMM的解码过程,WFST的维特比解码也是逐帧推进的。当featurepipeline buffer中的音频帧达到一定数目后,会先对音频帧计算声学得分,然后结合转移弧上的权重,得到每个时刻扩展路径的累计代价,即Token中的cost。HMM的维特比解码过程是对比来自上一时刻不同状态的累计代价,然后选择概率较高的状态保留下来,以便后续回溯最优路径。而WFST的维特比解码过程则是,通过对比指向同一状态的不同路径的由Token保存的累计代价(该Token与状态节点相关联,如该状态节点还没有Token,则创建一个新的Token),选择代价更小的路径并更新Token。
Kaldi中SimpleDecoder中的核心循环解码过程如下:
for(int32 frame = 0; !decodable.IsLastFrame(frame-1); frame++) {
ClearToks(prev_toks_);
std::swap(cur_toks_, prev_toks_);
ProcessEmitting(decodable, frame);
ProcessNonemitting();
PruneToks(cur_toks_, beam_);
}
其中数据结构cur_toks_,prev_toks_分别存储当前帧以及上一帧的activate tokens,起始时即第0帧,cur_toks_, prev_toks_都为空,当第一个loop结束后,cur_toks_中存储着第0帧生成的Token,当第二帧开始时会先将prev_toks情况并将cur_toks_中的内容转移到prev_toks当中,这时cur_toks变为空,而后对上一帧产生的Token再按照发射弧ProcessEmitting与非发射弧ProcessNonemitting分别进行处理产生新的Token List存到cur_toks_当中,以此类推循环直至最后一帧结束。loop中的最后一步PruneToks是按照给定的beam数对路径上的Token数目进行剪枝处理以防扩展路径过大影响解码效率。
可以看出每个循环loop中,ProcessEmitting与ProcessNoemitting两步是比较关键的。在前面我们提到过HCLG中的状态弧可能是会产生观察状态,也可能不会产生观察状态,那么ProcessEmitting就是对发射弧做处理,而rocessNoemitting则是对非发射弧做处理。下面是一个简单的WFST网络,该网络包括起始和结尾状态。实线表示发送转移弧(Emitting Arc),即观察值参数声学得分(acoustic_cost);虚线表示非发送转移弧(Nonemitting Arc),即不产生观察值无声学得分。每条转移弧上都有其对应的图代价。
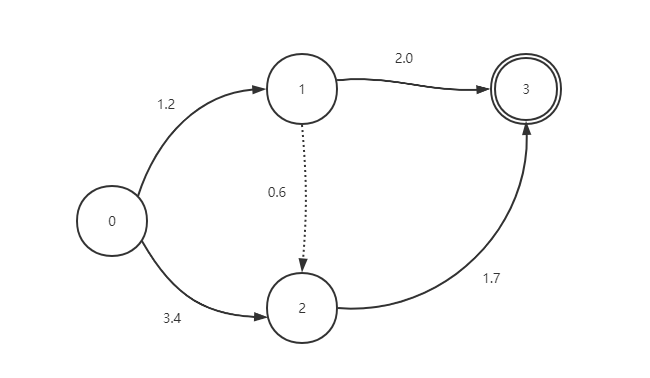
ProcessingEmitting() 函数针对prev_toks_存储的候选Token(即上一帧中产生的Token)对每一个Token的arc.nextstate挨个遍历发射到下一个状态,若此状态还没有Token则创建新的Token,若已存在则更新Token信息。
for all tokens old_tok in prev_toks
{
u = old_tok.key;
for all emitting arc (u,v)
{
cost = old_tok.cost;
cost += arc.weight + acoustic_cost(frame);
Add/Replace new Token for v if cost is lower;
}
}
ProcessingNonemitting() 函数则只处理当前帧生成的Token即_cur_toks_,因为是非发射弧不需要计算声学代价,所以只需要把之前的累计代价与转移弧权重相加即可得到新的累计代价。同样,如代价比之前Token低则进行更新,若无则生成新的Token。另外,在ProcessingNonemitting()中可能会处理一连串的epslions,通常会用队列来存储需要处理的状态。
Add all tokens in cur_toks in a queue q
while (!q.empty)
{
u = q.pop();
for all nonemitting arc (u,v)
{
cost = old_tok.cost
cost += arc.weight
Add/Replace new Token for v if cost is lower;
Add new token into q;
}
}
结语:
SimpleDecoder是一直最简单的WFST解码器,但是仅仅凭借语言描述还是有些晦涩,在洪青阳老师的《语音识别》一书中从P181-185有简洁的从起始状态开始到结束状态的WFST解码器处理流程及相关数据状态等的传播示意图,个人感觉对理解很有帮助,有兴趣的同学可以参考下。另外,WFST解码器家族中还有很多不同的decoder,如比较常用的LatticeDecoder(解码生成栅格网络)、BiglmDecoder(引入大语言模型)等等,设计都非常的有趣,很值得学习,后续有机会也会学习并做些介绍。
参考资料
- 语音识别:原理与应用(洪青阳)
- Kaldi Doc