
CTC序列建模
我们知道语音识别任务是一种从序列到序列的转换,如果去做一个语音识别的任务,给定音频$X$和对应标注$Y$,因为对于每一条音频及其标注$X$与$Y$的长度都是变化不等的,那么该如何去考虑音频与标注文本之间的对应关系?传统语音识别中利用HMM对序列进行建模,解决输入与输出之间的对应关系。对于端到端的语音识别任务CTC也可以实现这一功能。
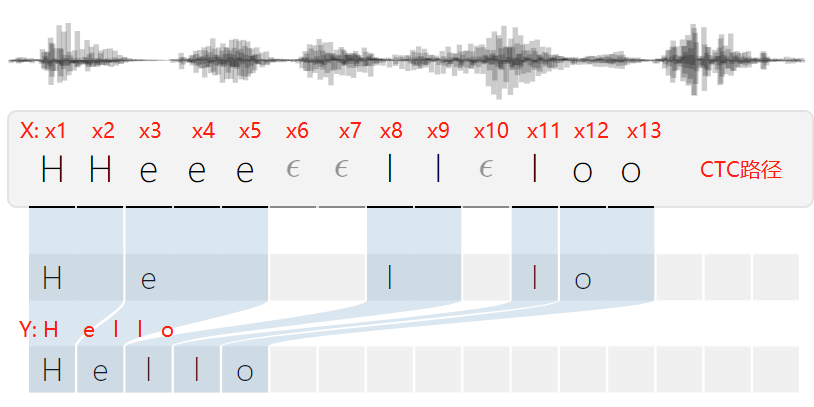
利用CTC可以直接对序列数据进行学习,不需要帧级别的标注,而在输出序列(CTC序列)和最终标签(CTC规整序列)之间增加了多对一的空间映射,并在此基础上定义了损失函数,在训练的过程中自动对齐并使损失函数最小化。
定义$L$为建模单元集,建模单元可以是字符,如英文字母{a,b,c…,z},可以是音素,也可以是汉字。为了对静音、字间停顿、字间混淆进行建模,CTC引入了额外的空白符标签blank“-”,并把建模单元集$L$扩展为$L^{‘}$(即$L^{‘}=L\bigcup blank $)。在识别的最后通过将空白符剔除得到规整的字符序列作为识别结果。
假设训练集为$S$,每个样本$(X,Y)$由输入序列$X={x_1,x_2,…,x_T}$和输出序列$Y=y_1,y_2,…,y_U$组成,其中$X$为音频($x_t$为第$t$帧音频特征),$Y$为标注序列,$T$为输入序列的长度,$U$则是输出序列的长度,$Y$的每个标注来自于建模单元集$L$(对于中文建模单元一般为汉字),CTC的训练目标是是$X$和$Y$尽量匹配,即最大化后验概率$P(Y\mid X)$,输入的序列经过解码之后,通过CTC衡量其和正确的序列是否接近。
我们提到过上述的最终真实输出序列$Y$其实是经过规整过后的字符串序列,那么序列$Y$可能是通过各种CTC路径$A_{ctc}(X,Y)$ 规整后生成的,这些路径包含了标注重复与空白标签blank的各种可能组合,例如,对于输出序列abc,$T=6$时,其可能由以下CTC路径生成:
-
aabbbc
-
abbccc
-
a-bbb-c
-
-a-b-c
-
-abb-c
其中“-”为blank表示空白符号,多个连续重复字符表示连续多帧特征均对应同一个字符,如aa表示为一个a,如果要表示aa则中间需要加入空白符如“a-a”。
穷举所有可能的CTC路径$A_{ctc}(X,Y)$,则$Y$由$X$生成的概率为:
\[P(Y\mid X)=\sum_{\hat{Y}\in A_{ctc}(X,Y)}P(\hat{Y}\mid X) \tag{1.1}\]其中,$\hat{Y}$表示$X$和$Y$在CTC网络下的其中某一条对齐路径,其长度和输入序列$X$一致,即$\hat{Y}={\hat{y}_1,\hat{y}_2…,\hat{y}_T}$。由$\hat{Y}$去除重复和空白标签后我们可以得到规整字符串序列$Y$。
对于单一对其路径$\hat{Y}$,其出现的概率等于其从$1$至$T$每帧的输出概率的累积:
\[P(\hat{Y}\mid X) = \prod_{t=1}^TP(\hat{y}_t\mid x_t),\forall \hat{Y}\in{L^{'T}} \tag{1.2}\]其中,$\hat{y}$表示路径 $\hat{Y}$在$t$时刻的输出标签($L^{’}$中的一个),$P(\hat{y}_t\mid x_t)$是其对应的输出概率。则上式表示整条CTC路径$\hat{Y}$的出现概率为从$1$到$T$每个时刻输出概率的乘积。
假设扩展建模单元集$L^{‘}$的个数为$K$,则CTC输出层对应$K$个节点。每个节点的最后输出$p_t^{k}$对应$t$时刻第$k$个建模单元的概率,其是由Encoder的隐藏层输出$h_t^{k}$经过Softmax函数转换得到的:
\[p_t^k=\frac{e^{h_t^k}}{\sum_{k=1}^Ke{h_t^k}} \tag{1.3}\]对于在某个时刻的输出$\hat{y}_t$ ,根据其在建模单元集的索引选择$K$个输出值的其中一个,如果对应的索引为3,则其值为$p_t^3$,即$P(\hat{y}_t\mid x_t)=p_t^3$。
基于输入序列$X$,CTC的某条对齐路径$\hat{Y}$的输出概率$P(\hat{Y}\mid X)$完整的计算过程如下图所示:
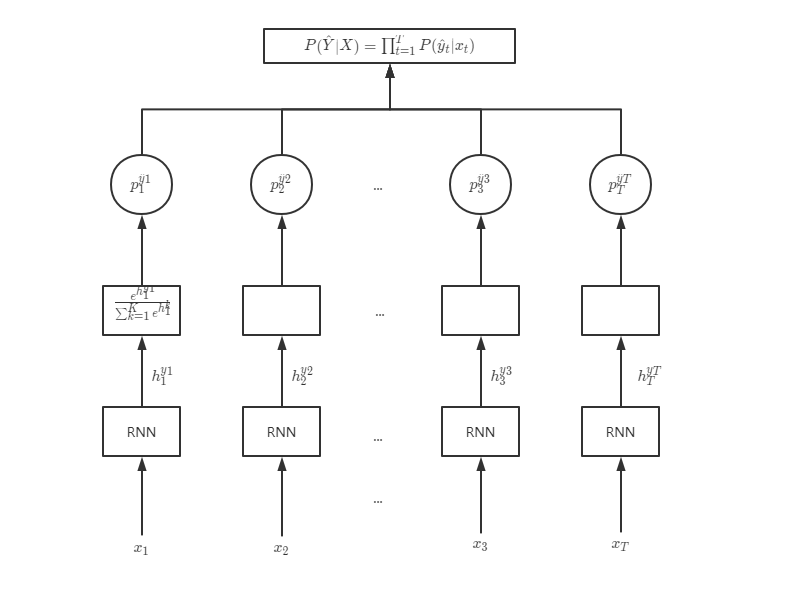
针对输入序列$X={x_1,x_2,…x_T}$,令其每一帧分别通过RNN模型得到隐藏层输出${h_1^{\hat{y}_1},h_2^{\hat{y}_2},…h_T^{\hat{y}_T}}$,再通过softmax转换得到每一帧的输出概率$p_t^{\hat{y}_t}$,再将这些概率连乘得到$P(\hat{Y}\mid X)$,即公式(1.2)
又因为$X$与$Y$之间可能有多条对齐路径,分别单独计算概率后,将所有可能路径概率相加得到总的后验概率$P(Y\mid X)$,即公式(1.1)
CTC Loss计算
CTC的本质上还是声学模型,其损失函数被定义为训练集$S$所有样本的负对数概率之和:
\[L(S)=-\sum_{(X,Y)\in S}lnP(Y\mid X) \tag{1.4}\]CTC训练优化的目标是使$L(S)$最小化,但计算$P(Y\mid X)$的复杂的非常高,为简化计算过程,可参照HMM的前向后向算法来求解CTC的局部和全局概率。
前向算法
在输出序列$Y=y_1,y_2,…,y_U$的句子头尾和每个标签中间添加空白符,表示为$Y‘$,即$Y’={b,y_1,b,y_2,…,y_U,b}\Rightarrow y_1^{‘},y_2^{‘},…y_{2U+1}^{‘}$
其中$b$表示空白符,$Y$的长度为$U$,则$Y’$的长度为$2U+1$。引入$\alpha_t(s)$来表示已经输出部分观察值$x_1,x2,..x_t$,并且到达标签为s的状态的概率: \(\alpha_t(s)=P(x_1,x_2,..x_t,s) \tag{1.5}\) 前向算法按输入序列的时间顺序,从前向后地推计算输出概率。具体计算步骤如下:
初始化:
\[\begin{align} \alpha_1(1)&=P(b\mid x_1) \\ \alpha_1(2)&=P(y^{'}\mid x_1) \\ \alpha_1(s)&=0, \forall s>2 \\ \end{align} \tag{1.6}\]迭代计算:
\[\alpha_{t+1}(s)= \begin{cases} (\alpha_t(s)+\alpha_t(s-1))P(y^{'}\mid x_t)\space, if\space y_s^{'}=b \space or \space y_{s-2}^{'}=y_s^{'} \\ (\alpha_t(s)+\alpha_t(s-1)+\alpha_t(s-2))P(y^{'}\mid x_t),\space otherwise \end{cases} \tag{1.7}\]终止计算:
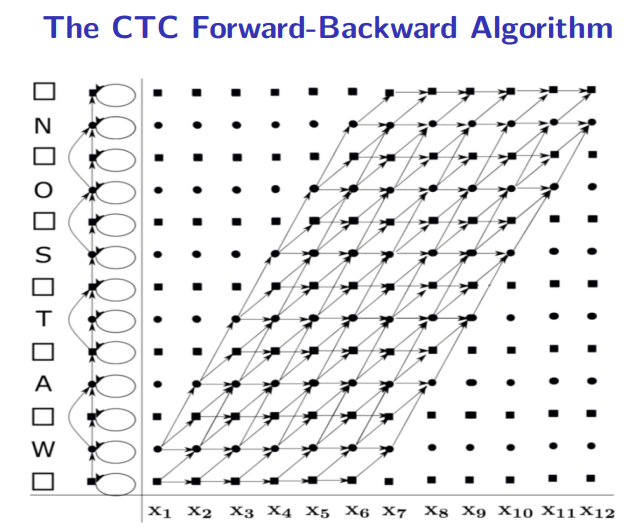
\[P(Y\mid X)=\alpha_T(2U+1)+\alpha_T(2U) \tag{1.8}\]如下图给出英文单词WATSON,首先为其加上空白标签变成“-W-A-T-S-O-N-”,其中“-”在图中为方块,字母为圆圈。拓展后$Y^{‘}$长度为13,$X$长度为12,则我们总共需要计算13*12个中间结果。

根据公式1.7,方块只能向前或向上移动一格,即不能跳到下一个空白字符。而实心圆圈除了可以向前或向上移动一格外,如果和下一个字母不同,也可以向上移动两格。

后向算法
后向算法由后向前推算输出概率。用$\beta_t(s)$表示在t时刻的标签为s及输出观察概率为$x_t,x_{t+1},…,x_T$ \(\beta_t(s)=P(x_t,x_{t+1},...,x_T) \tag{1.9}\) 扩展输出序列$Y’=b,y_1,b,y_2,…y_u,b\space$的长度为2U+1。则后向算法迭代过程如下:
初始化:
\[\begin{align} \beta_T(2U+1) &= P(y'_{2U+1}\mid x_T) \\ \beta_T(2U) &= P(y'_{2U}\mid x_T) \\ \beta_T(s) &= 0,\forall s<2U \end{align}\]迭代计算:
\[\beta{t+1}(s)= \begin{cases} (\beta_{t+1}(s)+\beta_{t+1}(s+1))P(y'_s\mid x_t), \space if \space y'_s=b \space or \space y'_{s+2}=y'_s\\ (\beta_{t+1}(s)+\beta_{t+1}(s+1)+\beta_{t+2}(s+2))P(y'_s\mid x_t), \space otherwise \end{cases}\]CTC Loss计算代码:
// Copyright (c) 2018 MathInf GmbH, Thomas Viehmann
// Licensed under the BSD-3-Clause license
// This is the CPU implementation of the Connectionist Temporal Loss.
// We mostly follow Graves.
// 1. Graves et al: http://www.cs.toronto.edu/~graves/icml_2006.pdf
// We use the equations from above link, but note that [1] has 1-based indexing and we (of course) use 0-based.
// Graves et al call the probabilities y, we use log_probs (also calling them inputs)
#include <ATen/ATen.h>
#include <ATen/Dispatch.h>
#include <ATen/Parallel.h>
#include <ATen/TensorUtils.h>
#include <ATen/native/Fill.h>
#include <numeric>
#include <type_traits>
namespace at {
namespace native {
namespace {
// this ad-hoc converts from targets (l in [1]) to augmented targets (l' in [1]) note that no bound-checking is done
// 用于查看当前位置的label,以便按公式1.7中两种情况进行计算
template<typename target_t>
static inline int64_t get_target_prime(target_t* target, int64_t offset, int64_t stride, int64_t idx, int64_t BLANK) {
if (idx % 2 == 0) {
return BLANK;
} else {
return target[offset + stride * (idx / 2)];
}
}
// This kernel is a relatively straightforward implementation of the alpha calculation in the forward backward algorithm (section 4.1).
// A (minor) twist is that we are using log-calculations to enhance numerical stability (log_probs and log_alpha).
// The function returns the loss and the alphas, the alphas are kept for the backward step. The wrapper (ctc_loss below) hides
// the alphas from the user by only returning the loss.
// cpu版ctc loss 前向计算
template<typename scalar_t, ScalarType target_scalar_type>
std::tuple<Tensor, Tensor> ctc_loss_cpu_template(const Tensor& log_probs, const Tensor& targets, IntArrayRef input_lengths, IntArrayRef target_lengths, int64_t BLANK) {
// log_probs: input_len x batch_size x num_labels
// targets [int64]: batch_size x target_length OR sum(target_lengths)
constexpr scalar_t neginf = -std::numeric_limits<scalar_t>::infinity();
using target_t = typename std::conditional<target_scalar_type == kInt, int, int64_t>::type;
CheckedFrom c = "ctc_loss_cpu";
auto log_probs_arg = TensorArg(log_probs, "log_probs", 1); // log概率
auto targets_arg = TensorArg(targets, "targets", 2); // 输出label 即 Y'标签
checkScalarType(c, targets_arg, target_scalar_type);
checkDim(c, log_probs_arg, 3);
checkDimRange(c, targets_arg, 1, 3);
int64_t batch_size = log_probs.size(1);
int64_t num_labels = log_probs.size(2);
TORCH_CHECK((0 <= BLANK) && (BLANK < num_labels), "blank must be in label range");
TORCH_CHECK((int64_t) input_lengths.size() == batch_size, "input_lengths must be of size batch_size");
TORCH_CHECK((int64_t) target_lengths.size() == batch_size, "target_lengths must be of size batch_size");
// NOLINTNEXTLINE(cppcoreguidelines-init-variables)
size_t tg_target_stride;
int64_t max_target_length = 0;
std::vector<int64_t> tg_batch_offsets(batch_size);
// 按照target(输出)维度维度情况取得strie
if (targets.dim() == 1) { // concatenated targets
int64_t pos = 0;
for (int64_t i = 0; i < batch_size; i++) {
tg_batch_offsets[i] = pos;
pos += target_lengths[i];
if (max_target_length < target_lengths[i])
max_target_length = target_lengths[i];
}
tg_target_stride = targets.stride(0);
checkSize(c, targets_arg, 0, pos);
}
else { // batch * max_target_length
// dim is 2
int64_t tg_batch_stride = targets.stride(0);
for (int64_t i = 0; i < batch_size; i++) {
tg_batch_offsets[i] = i * tg_batch_stride;
if (max_target_length < target_lengths[i])
max_target_length = target_lengths[i];
}
tg_target_stride = targets.stride(1);
checkSize(c, targets_arg, 0, batch_size);
TORCH_CHECK(targets.size(1) >= max_target_length,
"Expected tensor to have size at least ", max_target_length, " at dimension 1, but got size ", targets.size(1), " for ", targets_arg,
" (while checking arguments for ", c, ")");
}
int64_t max_input_length = log_probs.size(0);
for (int64_t b = 0; b < batch_size; b++) {
TORCH_CHECK(input_lengths[b] <= max_input_length,
"Expected input_lengths to have value at most ", max_input_length, ", but got value ", input_lengths[b],
" (while checking arguments for ", c, ")");
}
// log_alpha 用来存储前向各个状态的概率
Tensor log_alpha = at::empty({batch_size, log_probs.size(0), 2*max_target_length+1}, log_probs.options());
Tensor neg_log_likelihood = at::empty({batch_size}, log_probs.options());
auto lpp = log_probs.permute({1,0,2});
auto log_probs_a_global = lpp.accessor<scalar_t, 3>();
auto log_alpha_a_global = log_alpha.accessor<scalar_t, 3>();
auto targets_data = targets.data_ptr<target_t>();
auto neg_log_likelihood_a = neg_log_likelihood.accessor<scalar_t, 1>();
// alpha calculation for the first row, the three equations for alpha_1 above eq (6)
// first the default
log_alpha.narrow(1, 0, 1).fill_(neginf);
at::parallel_for(0, batch_size, 0, [&](int64_t start, int64_t end) {
// 最外层为batch循环
for (int64_t b = start; b < end; b++) {
int64_t input_length = input_lengths[b]; //输入维度即帧数X
int64_t target_length = target_lengths[b]; //输出维度即label长度Y
auto log_probs_a = log_probs_a_global[b]; // P
auto log_alpha_a = log_alpha_a_global[b]; // 前向alpha
int64_t tg_batch_offset = tg_batch_offsets[b];
// the first two items of alpha_t above eq (6)
// 前向初始化
log_alpha_a[0][0] = log_probs_a[0][BLANK];
if (target_length > 0)
log_alpha_a[0][1] = log_probs_a[0][get_target_prime(targets_data, tg_batch_offset, tg_target_stride, 1, BLANK)];
// now the loop over the inputs
// 下面就是针对单条音频的前向计算了
// 外层for为时间帧t,内层为当前帧对应的状态
for (int64_t t=1; t<input_length; t++) {
for (int64_t s=0; s<2*target_length+1; s++) {
// 当前状态s
auto current_target_prime = get_target_prime(targets_data, tg_batch_offset, tg_target_stride, s, BLANK);
// this loop over s could be parallel/vectorized, too, but the required items are one index apart
// alternatively, one might consider moving s to the outer loop to cache current_target_prime more (but then it needs to be descending)
// for the cuda implementation, that gave a speed boost.
// This is eq (6) and (7), la1,2,3 are the three summands. We keep track of the maximum for the logsumexp calculation.
scalar_t la1 = log_alpha_a[t-1][s];
scalar_t lamax = la1;
scalar_t la2, la3;
if (s > 0) {
la2 = log_alpha_a[t-1][s-1];
if (la2 > lamax)
lamax = la2;
} else {
la2 = neginf;
}
// 当前状态大于1且不为blank、不与s-2相同
if ((s > 1) && (get_target_prime(targets_data, tg_batch_offset, tg_target_stride, s-2, BLANK) !=
current_target_prime)) {
la3 = log_alpha_a[t-1][s-2];
if (la3 > lamax)
lamax = la3;
} else {
la3 = neginf;
}
if (lamax == neginf) // cannot do neginf-neginf
lamax = 0;
// this is the assignment of eq (6)
log_alpha_a[t][s] = std::log(std::exp(la1-lamax)+std::exp(la2-lamax)+std::exp(la3-lamax))+lamax + log_probs_a[t][current_target_prime];
}
}
// the likelihood is the the sum of the last two alphas, eq (8), the loss is the negative log likelihood
if (target_length == 0) {
// if the target is empty then there is no preceding BLANK state and hence there is no path to merge
neg_log_likelihood_a[b] = -log_alpha_a[input_length-1][0];
} else {
// 公式1.8
scalar_t l1 = log_alpha_a[input_length-1][target_length*2];
scalar_t l2 = log_alpha_a[input_length-1][target_length*2-1];
scalar_t m = std::max(l1, l2);
m = ((m == neginf) ? 0 : m);
scalar_t log_likelihood = std::log(std::exp(l1-m)+std::exp(l2-m))+m;
neg_log_likelihood_a[b] = -log_likelihood;
}
}
});
return std::make_tuple(neg_log_likelihood, log_alpha);
}
// This is the backward. It consists of two phases:
// a) computing the beta analogous to the alphas in the forward (backward half of the forward-backward algorithm) (eq (10) and (11))
// b) collecting the per-activation characters for all s and wrapping the gradient (eq (16), the collection is the sum)
// ctc loss 后向计算, 注意参数中包含了前向计算的结果log_alpha, 所以过程包括后向计算后的梯度计算及更新
template<typename scalar_t, ScalarType target_scalar_type>
Tensor ctc_loss_backward_cpu_template(const Tensor& grad_out, const Tensor& log_probs, const Tensor& targets, IntArrayRef input_lengths, IntArrayRef target_lengths, const Tensor& neg_log_likelihood, const Tensor& log_alpha, int64_t BLANK, bool zero_infinity) {
constexpr scalar_t neginf = -std::numeric_limits<scalar_t>::infinity();
using target_t = typename std::conditional<target_scalar_type == kInt, int, int64_t>::type;
int64_t max_input_length = log_probs.size(0);
int64_t batch_size = log_probs.size(1);
int64_t num_labels = log_probs.size(2);
Tensor grad = at::full_like(log_probs, neginf, LEGACY_CONTIGUOUS_MEMORY_FORMAT); // at this point, this is log of empty sum
// The admin bits. We don't do much checking and assume that the forward did.
// NOLINTNEXTLINE(cppcoreguidelines-init-variables)
int64_t tg_target_stride;
// NOLINTNEXTLINE(cppcoreguidelines-init-variables)
int64_t max_target_length;
std::vector<int64_t> tg_batch_offsets(batch_size);
if (targets.dim() == 1) { // concatenated targets
int64_t pos = 0;
max_target_length = 0;
for (int64_t i = 0; i < batch_size; i++) {
tg_batch_offsets[i] = pos;
pos += target_lengths[i];
if (max_target_length < target_lengths[i])
max_target_length = target_lengths[i];
}
tg_target_stride = targets.stride(0);
}
else { // batch x max_target_length
// dim is 2
int64_t tg_batch_stride = targets.stride(0);
for (int64_t i = 0; i < batch_size; i++) {
tg_batch_offsets[i] = i * tg_batch_stride;
}
tg_target_stride = targets.stride(1);
max_target_length = targets.size(1);
}
Tensor log_beta = at::empty_like(log_alpha, LEGACY_CONTIGUOUS_MEMORY_FORMAT); // could be optimized to use only 2 rows
auto lpp = log_probs.permute({1,0,2});
auto log_probs_a_global = lpp.accessor<scalar_t, 3>();
auto log_alpha_a_global = log_alpha.accessor<scalar_t, 3>();
auto log_beta_a_global = log_beta.accessor<scalar_t, 3>();
auto gp = grad.permute({1,0,2});
auto grad_a_global = gp.accessor<scalar_t, 3>();
auto targets_data = targets.data_ptr<target_t>();
auto create_fill_iterator = [](const Tensor& tensor, IntArrayRef squash_dims) {
return TensorIteratorConfig()
.set_check_mem_overlap(false) // Fill is idempotent, so overlap is okay
.check_all_same_dtype(false)
.add_output(tensor)
.resize_outputs(false)
.declare_static_shape(tensor.sizes(), squash_dims)
.build();
};
const auto fill_iter = create_fill_iterator(grad, /*squash_dims=*/1);
const auto fill_1d_iter = create_fill_iterator(grad, /*squash_dims=*/{0, 1});
const auto fill_log_beta_1d_iter = create_fill_iterator(log_beta, /*squash_dims=*/{0, 1});
at::parallel_for(0, batch_size, 0, [&](int64_t start, int64_t end) {
TensorIterator fill_iter_local(fill_iter);
TensorIterator fill_1d_iter_local(fill_1d_iter);
TensorIterator fill_log_beta_1d_iter_local(fill_log_beta_1d_iter);
for (int64_t b = start; b < end; b++) {
scalar_t nll = neg_log_likelihood.accessor<scalar_t, 1>()[b];
auto grad_a = grad_a_global[b];
if (zero_infinity && nll == std::numeric_limits<scalar_t>::infinity()) {
// grad_batch.zero_();
fill_iter_local.unsafe_replace_operand(0, grad_a.data());
fill_stub(kCPU, fill_iter_local, 0);
continue;
}
auto log_probs_a = log_probs_a_global[b];
auto log_alpha_a = log_alpha_a_global[b];
auto log_beta_a = log_beta_a_global[b];
int64_t input_length = input_lengths[b];
int64_t target_length = target_lengths[b];
int64_t tg_batch_offset = tg_batch_offsets[b];
// the initialization of beta before eq (10)
// here we do the fill for each batch item separately, as the input lengths will differ, so the t in which
// we start varies
if (input_length > 0) {
// log_beta.select(0, b).select(1, input_length-1).fill_(neginf);
fill_log_beta_1d_iter_local.unsafe_replace_operand(
0, log_beta_a[input_length - 1].data());
fill_stub(kCPU, fill_log_beta_1d_iter_local, neginf);
//后向结果
log_beta_a[input_length-1][2*target_length] = log_probs_a[input_length-1][BLANK];
//梯度计算
grad_a[input_length-1][BLANK] = log_alpha_a[input_length-1][2*target_length] + log_beta_a[input_length-1][2*target_length];
if (target_length > 0) {
auto current_target_prime = get_target_prime(targets_data, tg_batch_offset, tg_target_stride, 2*target_length-1, BLANK);
log_beta_a[input_length-1][2*target_length-1] = log_probs_a[input_length-1][current_target_prime];
// the first two are a blank and a non-blank, so we know they are different and we don't need to do log+
grad_a[input_length-1][current_target_prime] = log_alpha_a[input_length-1][2*target_length-1] + log_beta_a[input_length-1][2*target_length-1];
}
}
// now loop applying eq (10) / (11)
for (int64_t t=input_length-2; t>=0; t--) {
// this loop over s could be parallel/vectorized and doesn't really need to be descending...
// alternatively, one might consider moving s to the outer loop to cache current_target_prime more (but then it needs to be descending)
// for the cuda implementation, that gave a speed boost.
for (int64_t s=2*target_length; s>=0; s--) {
scalar_t lb1 = log_beta_a[t+1][s];
scalar_t lbmax = lb1;
scalar_t lb2, lb3;
auto current_target_prime = get_target_prime(targets_data, tg_batch_offset, tg_target_stride, s, BLANK);
if (s < 2*target_length) {
lb2 = log_beta_a[t+1][s+1];
if (lb2 > lbmax)
lbmax = lb2;
} else {
lb2 = neginf;
}
if ((s < 2*target_length-1) && (get_target_prime(targets_data, tg_batch_offset, tg_target_stride, s+2, BLANK) !=
current_target_prime)) {
lb3 = log_beta_a[t+1][s+2];
if (lb3 > lbmax)
lbmax = lb3;
} else {
lb3 = neginf;
}
if (lbmax == neginf)
lbmax = 0;
log_beta_a[t][s] = std::log(std::exp(lb1-lbmax)+std::exp(lb2-lbmax)+std::exp(lb3-lbmax))+lbmax + log_probs_a[t][current_target_prime];
// one might check whether one can vectorize this better when done after the t-loop...
// now that we have beta, we fill in the sum of alpha*beta in eq (16)
// in contrast to the cuda implementation, we only parallelize over the batch, so we don't have a concurrency
// issue (several s can map to the same target character)
// collected[b, t, target'[s]] "log+=" log_alpha[t, s]+log_beta[t, s]
scalar_t log_alpha_beta = log_alpha_a[t][s] + log_beta_a[t][s];
scalar_t &lcab = grad_a[t][current_target_prime];
if (lcab == neginf) {
lcab = log_alpha_beta;
} else {
scalar_t max = std::max(lcab, log_alpha_beta);
lcab = std::log(std::exp(lcab-max)+std::exp(log_alpha_beta-max))+max;
}
}
}
// now grad has the sum of eq (16)
// now we wrap up the calculation by adding in the remaining items of eq (16)
// this could be a great target for further vectorization.
// grad is the output gradient, nll is the loss. Note that the likelihood -nll is the Z of eq (16)
scalar_t gr = grad_out.accessor<scalar_t, 1>()[b];
for (int64_t t = 0; t < input_length; t++) { // or go for the full thing?
for (int64_t c = 0; c < num_labels; c++) {
scalar_t& res = grad_a[t][c];
scalar_t lp = log_probs_a[t][c];
res = (std::exp(lp)-std::exp(res + nll - lp)) * gr;
}
}
// zero the remainder
for (auto l : c10::irange(input_length, max_input_length)) {
// grad_batch.select(0, l).zero_();
fill_1d_iter_local.unsafe_replace_operand(0, grad_a[l].data());
fill_stub(kCPU, fill_1d_iter_local, 0);
}
}
});
return grad;
}
} // namespace
std::tuple<Tensor, Tensor> ctc_loss_cpu(const Tensor& log_probs, const Tensor& targets, IntArrayRef input_lengths, IntArrayRef target_lengths, int64_t BLANK, bool zero_infinity) {
(void)zero_infinity; // only used for backwards
return AT_DISPATCH_FLOATING_TYPES(log_probs.scalar_type(), "ctc_loss_cpu", [&] {
if (targets.scalar_type() == kLong) {
return ctc_loss_cpu_template<scalar_t, kLong>(log_probs, targets, input_lengths, target_lengths, BLANK);
} else {
return ctc_loss_cpu_template<scalar_t, kInt>(log_probs, targets, input_lengths, target_lengths, BLANK);
}
});
}
Tensor ctc_loss_backward_cpu(const Tensor& grad, const Tensor& log_probs, const Tensor& targets, IntArrayRef input_lengths, IntArrayRef target_lengths,
const Tensor& neg_log_likelihood, const Tensor& log_alpha, int64_t BLANK, bool zero_infinity) {
return AT_DISPATCH_FLOATING_TYPES(log_probs.scalar_type(), "ctc_loss_backward_cpu", [&] {
if (targets.scalar_type() == kLong) {
return ctc_loss_backward_cpu_template<scalar_t,kLong>(grad, log_probs, targets, input_lengths, target_lengths, neg_log_likelihood, log_alpha, BLANK, zero_infinity);
} else {
return ctc_loss_backward_cpu_template<scalar_t,kInt>(grad, log_probs, targets, input_lengths, target_lengths, neg_log_likelihood, log_alpha, BLANK, zero_infinity);
}
});
}
// this wrapper function dispatches to the native and cudnn implementations and hides the alpha/grad from the user (by just returning the loss)
// the gradient is implemented for _cudnn_ctc_loss (just in derivatives.yaml) and _ctc_loss and this function has automatic gradients
// it also handles the reduction if desired
Tensor ctc_loss(const Tensor& log_probs, const Tensor& targets, IntArrayRef input_lengths, IntArrayRef target_lengths, int64_t BLANK, int64_t reduction, bool zero_infinity) {
bool use_cudnn =
(log_probs.device().type() == at::kCUDA) &&
at::_use_cudnn_ctc_loss(
log_probs, targets, input_lengths, target_lengths, BLANK);
Tensor res;
if (use_cudnn) {
// non-deterministic ctc loss on cudnn disabled due to inconsistent results
// see: https://github.com/pytorch/pytorch/issues/21680
res = std::get<0>(at::_cudnn_ctc_loss(log_probs, targets, input_lengths, target_lengths, BLANK, /*deterministic=*/true, zero_infinity));
} else {
// if the targets are on CPU (which you need for CuDNN, let's move them to
// GPU as a service for the user)
res = std::get<0>(at::_ctc_loss(
log_probs,
targets.to(log_probs.device(), kLong),
input_lengths,
target_lengths,
BLANK,
zero_infinity));
if (zero_infinity) {
res = at::where(res == Scalar(std::numeric_limits<double>::infinity()), at::zeros({}, res.options()), res);
}
}
if (reduction == at::Reduction::Mean) {
auto target_lengths_t =
at::tensor(target_lengths, res.options()).clamp_min(1);
return (res / target_lengths_t).mean();
} else if (reduction == at::Reduction::Sum) {
return res.sum();
}
return res;
}
// Convenience function accepting Tensors
Tensor ctc_loss(const Tensor& log_probs, const Tensor& targets, const Tensor& input_lengths, const Tensor& target_lengths, int64_t BLANK, int64_t reduction, bool zero_infinity) {
TORCH_CHECK(isIntegralType(input_lengths.scalar_type(), /*includeBool=*/false), "input_lengths must be integral");
TORCH_CHECK(isIntegralType(target_lengths.scalar_type(), /*includeBool=*/false), "target_lengths must be integral");
Tensor ilc = input_lengths.to(Device(at::kCPU), at::kLong).contiguous();
Tensor tlc = target_lengths.to(Device(at::kCPU), at::kLong).contiguous();
IntArrayRef il(ilc.data_ptr<int64_t>(), ilc.numel());
IntArrayRef tl(tlc.data_ptr<int64_t>(), tlc.numel());
return at::native::ctc_loss(log_probs, targets, il, tl, BLANK, reduction, zero_infinity);
}
} } // at::native
参考资料:
- 语音识别:原理与应用(洪青阳)
- https://zhuanlan.zhihu.com/p/42719047
- https://xiaodu.io/ctc-explained/
- https://fossies.org/linux/pytorch/aten/src/ATen/native/LossCTC.cpp